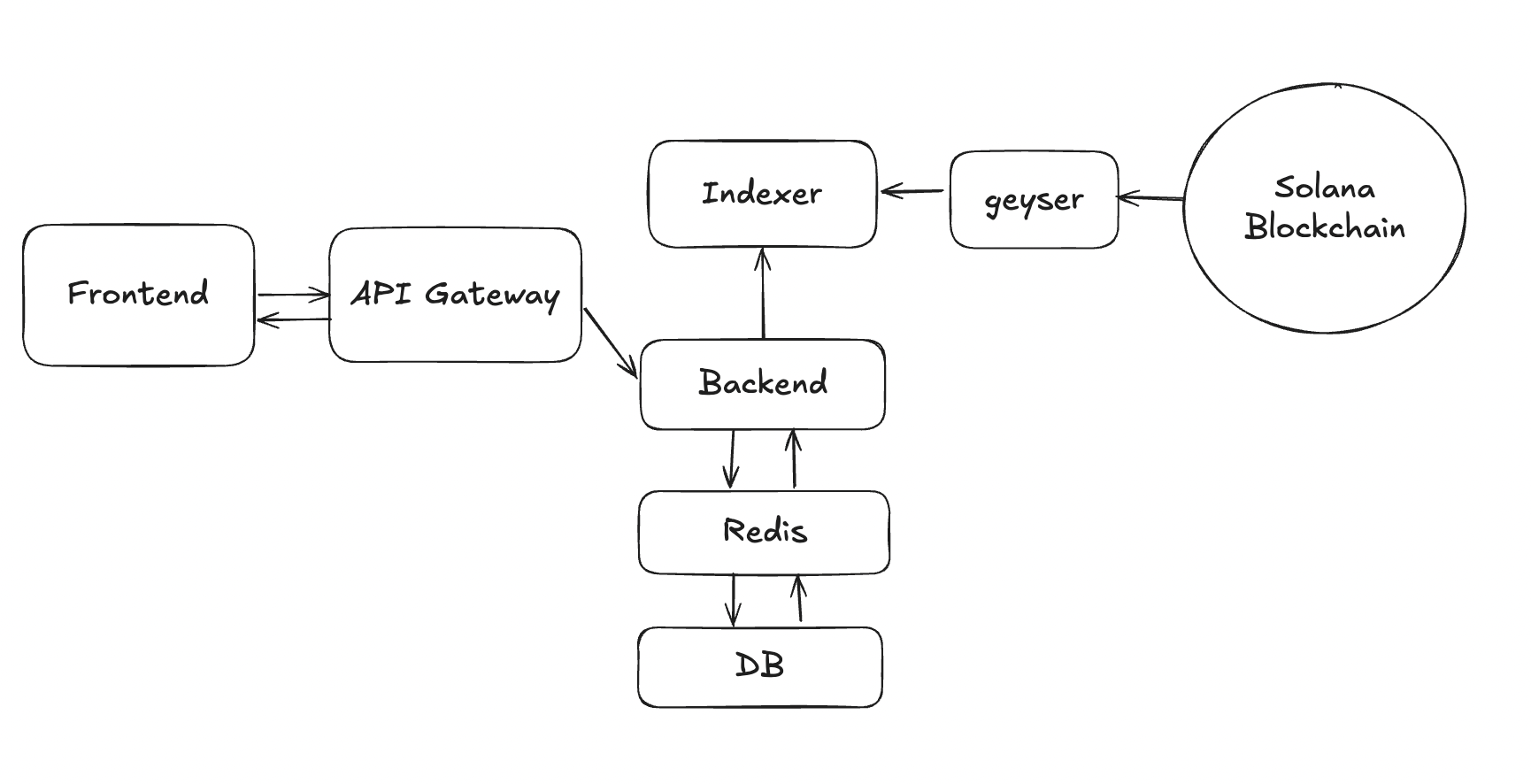
Backend Architecture
Data Flow
The backend provides data to the frontend via an API, with its primary responsibility being indexing blockchain data, such as transactions.
To achieve this, the indexer continuously queries the Solana blockchain and stores the relevant data for efficient retrieval.
Why Indexing?
The Need for Indexing
Raw blockchain data is not optimized for fast queries. Without indexing, fetching relevant information directly from the blockchain is inefficient because:
- Solana’s RPC nodes are not designed for historical queries. They focus on real-time transactions.
- Querying the blockchain directly is slow due to network latency and high computational costs.
- Data is often fragmented across multiple accounts and programs, requiring aggregation.
- APIs need structured responses, which indexing enables by organizing data efficiently.
By indexing blockchain data, we can:
- Provide fast API responses for applications.
- Enable historical data queries without overloading RPC nodes.
- Enhance scalability by reducing repeated network calls.
Indexing Solutions
Geyser Plugin
Geyser is a data streaming protocol on Solana that enables real-time indexing.
Yellowstone gRPC
A gRPC service utilizing the Geyser plugin for efficient blockchain data access.
- Accounts: Key, Owner,
getProgramAccounts - Transactions
- Blocks
Helius RPC Node
Helius provides a high-performance RPC service for interacting with the Solana blockchain.
getProgramAccount,getTransaction,getBlock: 10 credits per requestgetAsset,searchAsset: 10 credits per request
View Helius Pricing & Rate Limits
Helius Dedicated Node
For high-performance requirements, a dedicated node can be used.
Initially, the Helius RPC service is leveraged. However, in the future, Yellowstone, Geyser, or a Dedicated Node can be introduced as needed.
Backend Bottlenecks & Solutions
Several factors can cause performance bottlenecks, including:
- Database I/O latency
- Network delays
- RPC server limitations, such as hitting infrastructure limits, which may prevent data from being imported properly.
Mitigation Strategies
- Component isolation: Reduce dependencies between critical backend elements.
- Message queues: Implement middleware to enhance availability under heavy traffic.
Choosing the Right Database
The database choice depends on the data structure and scalability requirements.
| Scenario | Recommended Database |
|---|---|
| Structured data (e.g., transactions) | Relational DB (RDB) |
| Unstructured data (e.g., NFTs, social data) | NoSQL |
PostgreSQL + TimescaleDB
Ideal for time-series data (e.g., transactions on a DEX).
- Automatic partitioning: No manual maintenance required.
- Data compression: Efficient storage management.
- Pre-aggregated queries: Optimized retrieval for 1-minute, 1-hour intervals.
- PostgreSQL-compatible, allowing seamless integration.
MongoDB
Best suited for indexing diverse datasets (e.g., tokens, NFTs, social interactions).
- Scalable horizontal expansion when handling large datasets.
- Works well when time-series performance is not a priority (e.g., log collection).
- NoSQL flexibility enables efficient handling of varied data structures.
Overall Architecture (simple version)